marcelklehr / readability.php
A PHP port of Readability.js
Maintainers
Package info
github.com/marcelklehr/readability.php
Language:HTML
pkg:composer/marcelklehr/readability.php
Requires
- php: >=7.0.0
- ext-dom: *
- ext-mbstring: *
- ext-xml: *
- psr/log: ^1.0
Requires (Dev)
- monolog/monolog: ^1.24
- phpunit/phpunit: ^9.5
- voku/html-min: ^4.4
Suggests
- monolog/monolog: Allow logging debug information
This package is auto-updated.
Last update: 2026-07-29 02:40:57 UTC
README
PHP port of Mozilla's Readability.js. Parses html text (usually news and other articles) and returns title, author, main image and text content without nav bars, ads, footers, or anything that isn't the main body of the text. Analyzes each node, gives them a score, and determines what's relevant and what can be discarded.
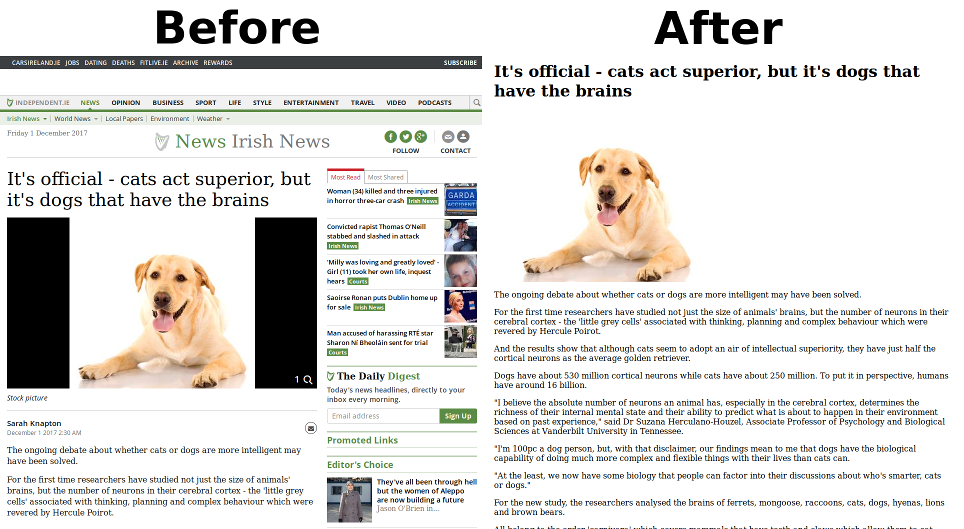
The project aim is to be a 1 to 1 port of Mozilla's version and to follow closely all changes introduced there, but there are some major differences on the structure. Most of the code is a 1:1 copy –even the comments were imported– but some functions and structures were adapted to suit better the PHP language.
Lead Developer: Andres Rey
Requirements
PHP 7.3+, ext-dom, ext-xml, and ext-mbstring. To install all this dependencies (in the rare case your system does not have them already), you could try something like this in *nix like environments:
$ sudo apt-get install php7.1-xml php7.1-mbstring
How to use it
First you have to require the library using composer:
composer require marcelklehr/readability.php
Then, create a Readability class and pass a Configuration class, feed the parse() function with your HTML and echo the variable:
use marcelklehr\Readability\Readability; use marcelklehr\Readability\Configuration; use marcelklehr\Readability\ParseException; $readability = new Readability(new Configuration()); $html = file_get_contents('http://your.favorite.newspaper/article.html'); try { $readability->parse($html); echo $readability; } catch (ParseException $e) { echo sprintf('Error processing text: %s', $e->getMessage()); }
Your script will output the parsed text or inform about any errors. You should always wrap the ->parse call in a try/catch block because if the HTML cannot be parsed correctly, a ParseException will be thrown.
If you want to have a finer control on the output, just call the properties one by one, wrapping it with your own HTML.
<h1><?= $readability->getTitle(); ?></h1> <h2>By <?= $readability->getAuthor(); ?></h2> <div class="content"><?= $readability->getContent(); ?></div>
Here's a list of the available properties:
- Article title:
->getTitle(); - Article content:
->getContent(); - Excerpt:
->getExcerpt(); - Main image:
->getImage(); - All images:
->getImages(); - Author:
->getAuthor(); - Text direction (ltr or rtl):
->getDirection();
If you need to tweak the final HTML you can get the DOMDocument of the result by calling ->getDOMDocument().
Options
You can change the behaviour of Readability via the Configuration object. For example, if you want to fix relative URLs and declare the original URL, you could set up the configuration like this:
$configuration = new Configuration(); $configuration ->setFixRelativeURLs(true) ->setOriginalURL('http://my.newspaper.url/article/something-interesting-to-read.html');
Also you can pass an array of configuration parameters to the constructor:
$configuration = new Configuration([ 'fixRelativeURLs' => true, 'originalURL' => 'http://my.newspaper.url/article/something-interesting-to-read.html', // other parameters ... listing below ]);
Then you pass this Configuration object to Readability. The following options are available. Remember to prepend set when calling them using native setters.
- MaxTopCandidates: default value
5, max amount of top level candidates. - CharThreshold: default value
500, minimum amount of characters to consider that the article was parsed successful. - ArticleByLine: default value
false, search for the article byline and remove it from the text. It will be moved to the article metadata. - StripUnlikelyCandidates: default value
true, remove nodes that are unlikely to have relevant information. Useful for debugging or parsing complex or non-standard articles. - CleanConditionally: default value
true, remove certain nodes after parsing to return a cleaner result. - WeightClasses: default value
true, weight classes during the rating phase. - FixRelativeURLs: default value
false, convert relative URLs to absolute. Like/testtohttp://host/test. - SubstituteEntities: default value
false, disables thesubstituteEntitiesflag of libxml. Will avoid substituting HTML entities. Likeáto á. - NormalizeEntities: default value
false, converts UTF-8 characters to its HTML Entity equivalent. Useful to parse HTML with mixed encoding. - OriginalURL: default value
http://fakehost, original URL from the article used to fix relative URLs. - SummonCthulhu: default value
false, remove all<script>nodes via regex. This is not ideal as it might break things, but might be the only solution to [libxml problems with unescaped javascript](https://github.com/ marcelklehr/readability.php#known-issues). If you're not parsing Javascript tutorials, it's recommended to always set this option astrue.
Debug log
Logging is optional and you will have to inject your own logger to save all the debugging messages. To do so, use a logger that implements the PSR-3 logging interface and pass it to the configuration object. For example:
// Using monolog
$log = new Logger('Readability');
$log->pushHandler(new StreamHandler('path/to/my/log.txt'));
$configuration->setLogger($log);
In the log you will find information about the parsed nodes, why they were removed, and why they were considered relevant to the final article.
Limitations
Of course the main limitation is PHP. Websites that load the content through lazy loading, AJAX, or any type of javascript fueled call will be ignored (actually, not ran) and the resulting text will be incorrect, compared to the readability.js results. All the articles you want to parse with readability.php need to be complete and all the content should be in the HTML already.
Known Issues
Javascript spilling into the text body
DOMDocument has some issues while parsing javascript with unescaped HTML on strings. Consider the following code:
<div> <!-- Offending div without closing tag --> <script type="text/javascript"> var test = '</div>'; // I should not appear on the result </script>
If you would like to remove the scripts of the HTML (like readability does), you would expect ending up with just one div and one comment on the final HTML. The problem is that libxml takes that closing div tag inside the javascript string as a HTML tag, effectively closing the unclosed tag and leaving the rest of the javascript as a string within a P tag. If you save that node, the final HTML will end up like this:
<div> <!-- Offending div without closing tag --> <p>'; // I should not appear on the result </p></div>
This is a libxml issue and not a Readability.php bug.
There's a workaround for this: using the summonCthulhu option. This will remove all script tags via regex, which is not ideal because you may end up summoning the lord of darkness.
  entities disappearing
  entities are converted to spaces automatically by libxml and there's no way to disable it.
Self closing tags rendering as fully expanded tags
Self closing tags like <br /> get automatically expanded to <br></br. No way to disable it in libxml.
Dependencies
Readability.php uses the PSR Log interface to define the allowed type of loggers. Monolog is only required on development installations. (--dev option during composer install).
To-do
- Keep up with Readability.js changes
- Add a small template engine for the __toString() method, instead of using a hardcoded one.
- Replace all the
iterator_to_arraycalls with a custom PHP generator that keeps track of the removed or altered nodes.
How it works
Readability parses all the text with DOMDocument, scans the text nodes and gives the a score, based on the amount of words, links and type of element. Then it selects the highest scoring element and creates a new DOMDocument with all its siblings. Each sibling is scored to discard useless elements, like nav bars, empty nodes, etc.
Testing
Any version of PHP installed locally should be enough to develop new features and add new test cases.
Code porting
Up to date with readability.js as of 19 Nov 2018.
License
Based on Arc90's readability.js (1.7.1) script available at: http://code.google.com/p/arc90labs-readability
Copyright (c) 2010 Arc90 Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.