unclecheese / silverstripe-blubber
Identifies unused CSS in your SilverStripe project
Maintainers
Package info
github.com/unclecheese/silverstripe-blubber
Type:silverstripe-module
pkg:composer/unclecheese/silverstripe-blubber
Requires
- sabberworm/php-css-parser: *
- symfony/css-selector: 2.5.*
- symfony/dom-crawler: 2.5.*
- symfony/finder: 2.6.*@stable
This package is auto-updated.
Last update: 2026-06-29 00:47:23 UTC
README
This module provides a task that scans your theme directory for css files, and checks all of their selectors against real HTML samples taken from your project. Those that match are placed in a "keep" file, and those that have no matches are placed in a "discard" (blubber) file.
Installation
composer require unclecheese/silverstripe-blubber:dev-master
Screenshot
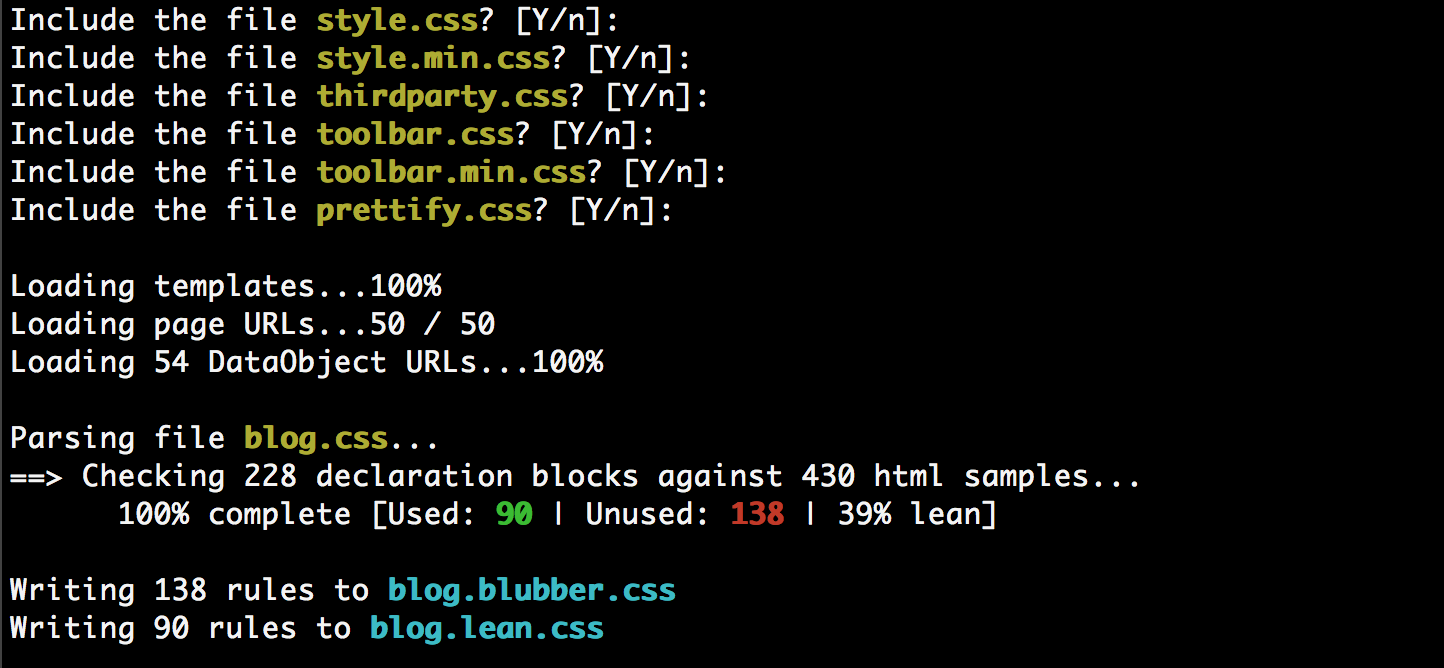
How it works
There are five stages to the task:
- Scan for theme CSS, and prompt the user for which files should be included in the assessment
- Gather all the templates in the manifest, and store their HTML
- Emulate HTTP requests against a sample of actual pages and DataObjects stored in the database, and store the rendered HTML
- Parse the CSS file, and check each declaration block against all the HTML samples, both static (unrendered) and dynamic (rendered via HTTP response)
- Cut two new files for each included CSS file:
myfile.lean.cssandmyfile.blubber.css, which contain the "good" rules and the "bad" rules, respectively.
Rationale
There are a few tools that do this already. Most of them work by spidering the site and building up a state of unused selectors. There are two major limitations with this approach:
- They don't account for various UI state changes that happen after page load (e.g. form validation)
- They do not future-proof against content that may not currently exist, but could likely be used further down the track, such as a page type, with a custom template, that simply hasn't been saved in the CMS yet.
Because almost all HTML is rendered through .ss files in SilverStripe, scanning all the templates provides nearly all possible UI state the project may have now or in the future.
However, there limitations to simply scanning .ss templates as static HTML. They do not account for content that may be relevant to CSS that is rendered dynamically, for instance: <body class="$ClassName"> or <input $AttributesHTML>. This content can only be obtained by generating a true rendering of the HTML.
Given these two sets of complimentary advantages and shortcomings, this module uses both approaches in serial, to produce as few false-positives as possible.
Limitations
Still, there are two main areas that will generate false positives:
- CSS selectors that depend on JavaScript DOM mutations, e.g.
"<ul class="draggable draggable-active..."> - Logged-in state, e.g.
<% if $Member %>$CommentForm<% end_if %>.
The tool should not be used without discretion, but rather, provide the lion's share of the CSS that needs to be removed.
Configuration
There are a few configuration options you can throw at the task that get passed off to the Sampler object. These are useful for adjusting the parameters around what database content gets spidered.
CSSBlubberTask: extra_dataobjects: [] omit: - RedirectorPage limits: {} default_limit: 3 theme_css_dir: 'base/production/css/'
extra_dataobjects: Allows you to specify a list of DataObjects whose URLs you want spidered, e.g.Product,ForumPost. NB: these objects must have aLink()method.omit: Classes to omit from the spiderlimits: A map of class names to the number of records that should be sampled., e.g.{ Product: 10 }will ensure that no more than 10 Product objects get their HTML scanned. If there are 1,000 products in the database, there's no need in scanning each one. They all use the same template and CSS, with little variation.default_limit: If no limit is specified for the class, this is the number that's applied.theme_css_dir: Specify a path where CSS resides for a theme
Todo
- Allow exclusions of module templates (e.g. framework)
- Break up this module into separate packages (Outputter, Sampler)