manofstrong / sitescrapper
A Package to Scrape Websites from their Sitemaps and Extract Relevant Content from the Webpage and Upload to a Database
Requires
- php: >= 7.0
- catfan/medoo: ^1.6
- donatello-za/rake-php-plus: ^1.0
- fabpot/goutte: ^3.2
- sters/extract-content: ^0.0.3
- sunra/php-simple-html-dom-parser: ^1.5
- vipnytt/sitemapparser: ^1.0
Requires (Dev)
This package is auto-updated.
Last update: 2026-07-14 04:07:22 UTC
README
A PHP library to scrape websites based on their sitemaps and extract relevant content from the webpages the content is then uploaded a database for later use.
The Sitemaps.org protocol is the leading standard and is supported by Google, Bing, Yahoo, Ask and many others and has now become an accepted means of displaying webpages in a website and their relevance. This has meant that most of the modern websites have implemented sitemaps which makes it easier for a web scrapper to avoid unnecessary measures to find the links and go straight to the source. Please note that the library can recursively parse through sitemaps so only one sitemap per website is needed.
This library also eliminates the need for exploring site specific html tags in search of the relevant content by stripping down the page content to the most important parts of the page by removing boilerplate and extracting the rest as full text. The library then obtains the keywords of the extracted text and the word count of the text. These are essential for later data analysis and keywords. Finally, the library uploads the content into MySQL database whose schema has been provided in the database folder of this project.
Basically, this is a blind bulk scrapping tool, just provide it with a list of sitemaps, run it. It will run for as long as it takes to scrape through the pages of the websites provided and upload them to the database for you.
This library is designed to be run from the Command Line rather than web browser. Please consider it a CLI tool and use it as such.
Features
- Sitemap parsing (either a single site, or a list of sites)
- Scrapping (relevant content extraction)
- Keyword extraction
- Word count of extracted data
- Custom User-Agent string
- Database uploading of extracted content
Sitemap Formats supported
- XML
.xml - Compressed XML
.xml.gz - Robots.txt rule sheet
robots.txt
Webpage Formats supported
- HTML
text/html
Sitemap File Formats supported
- Text
text/txt
Installation
The library is available for install via Composer. Just add this to your composer.json file:
{
"require": {
"manofstrong/sitescrapper": "^0.0.1"
}
}
Then run composer update.
Getting Started
Basic display example
Returns the content of a specified number of pages from a single sitemap. Does not store into database.
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $singleSitemapUrl = 'https://www.php.com/sitemap.xml'; // can be .xml or .xml.gz or robots.txt file $numberOfPages = 2; // must be a digit without single or double quotation marks: '2' or "2" will fail. $scrapeThisSite -> showContentSiteMap($singleSitemapUrl, $numberOfPages);
This command displays the content of each page as an array with the four elements the url, the title, the keywords, the content, and the word count as shown in the image below:
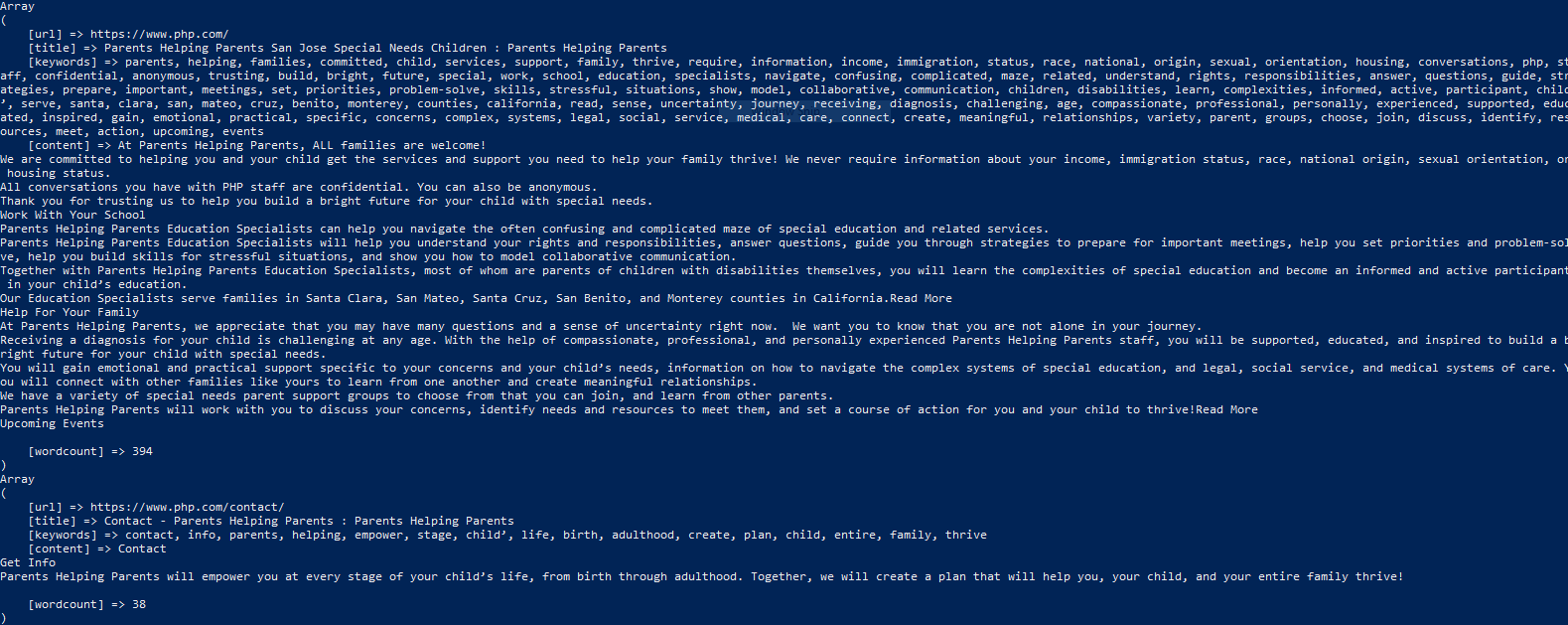
A single sitemap
Method to extract the webpages from a single sitemap. This will go through the sites and update the database provided. It will return the url and completion status.
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $singleSitemapUrl = 'https://www.php.com/sitemap.xml'; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> singleSiteMap($singleSitemapUrl);
Array of sitemaps
Method to extract the webpages from sitemaps provided via array. This will go through the sites in the array, and update the database provided. It will return the url and completion status. This is advisable if you have less than 10 different sites that you want to scrape.
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $sitemapArray = ['https://site1.com/sitemap.xml','https://site2.com/sitemap.xml','https://site3.com/sitemap.xml']; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> siteMapsArray($sitemapArray);
File of Sitemaps
Method to extract the webpages from sitemaps provided via array. This will go through the all sites in the file, and update the database provided. It will return the url and completion status. This is advisable if you have more than 10 different sites that you want to scrape.
The file must must a text file and the each sitemap must be in its own line without any other text. The urls must also be in compliance with the [RFC 2396](https://www.ietf.org/rfc/rfc2396.txt).
For the sitemap urls that are not compliant, the library will create a file called skippedeurls.txt and list them there. You can then go through this file making the corrections needed to ensure compliance.
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $sitemapFile = __DIR__ . '/yourtextfile.txt'; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> siteMapFile($sitemapFile);
Sample file structure
https://site1.com/sitemap.xml
https://site2.com/sitemap.xml
http://site3.com/sitemap.xml
https://site4.com/sitemap.xml
https://site5.com/sitemap.xml
https://site6.com/sitemap.xml
https://site7.com/sitemap.xml
https://site8.com/sitemap.xml
https://site9.com/sitemap.xml
https://site10.com/sitemap.xml
https://www.site11.com/sitemap.xml
https://www.site12.com/sitemap.xml
http://www.site13.com/sitemap.xml
https://www.site14.com/sitemap.xml
https://www.site15.com/sitemap.xml
https://www.site16.com/sitemap.xml
https://www.site17.com/sitemap.xml
https://www.site18.com/sitemap.xml
https://www.site19.com/sitemap.xml
https://www.site20.com/sitemap.xml
http://site21.com/sitemap.xml
Advanced setting of setting User Agent
Note: The default User Agent is ManofStrong SiteScrapper Tool v1.0 (+https://github.com/manofstrong/sitescrapper/)
If you want to change and have your own just use this method.
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $scrapeThisSite -> setUserAgent('Example User Agent. For Text Data Data Assigment.');
License:
SiteScrapper is under the MIT license.
Limitations:
This is not a precise data collection tools especially for those who want to obtain specific sections of a webpage to the exclusion of others. This library simply collects the most important section of the webpage such as large blocks of text. Therefore, this library best works for someone with the goal of massive text data collection and extraction for big data or other analytical research.
Usage Tip:
If you are running this on a remote server that you have ssh into, run it in a Screen to avoid interruptions. Learn more about the Linux Screen Command here.